多样性指数
Alpha多样性指数
Alpha多样性指数是用于观测单一种群内生物种类数量以及物种间相对多度的一种指数。有以下三个基本概念:
- 丰富度(Richness):群落内物种的数量。
- 丰度(Abundance):物种所包含的个体数量。
- 均匀度(Evenness):样本内不同物种所包含的个体数量的一致程度。
这里主要介绍Chao1指数、Shannon指数、Simpson指数。
Chao1指数
$$
S_1=S_{obs}+\frac{F^2_1}{2F_2}
$$
公式:Sobs为观察到的物种数,F1为只出现一次的物种数,F2为出现两次的物种数。
定义解释:在对群落样本进行抽样的时候如果还有没有被发现的物种,那么抽样的结果中就一直会存在只出现一次的物种,一直抽样直到没有只出现一次的物种时(也就是观察到的物种至少出现两次)就可以认为此时的被抽出的物种数目最接近样本的理论最高值。
Chao1指数越大,样本内的物种种类也就越多,Alpha多样性越高。
Shannon指数
$$
H=-\sum(P_i)(\log_2P_i)
$$
$$
P_i=\frac{n_i}{N}
$$
公式:Pi为第i种物种的个体数占总个体数N的比例。
定义解释:对整个群落的样本进行抽样,预测下一个抽到的物种是什么,该指数反映的就是抽取到的物种的不确定性。
群落的丰富度越高,且不同物种分布越均匀,那么就越难预测下个采集的物种是什么,不确定性也就越高,Shannon指数也就越大,Alpha多样性越高。
Simpson指数
$$
D_s=1-\sum^s_{i=1}p_i^2
$$
公式:Pi为第i种物种的个体数占总个体数的比例。
定义解释:在足够大的样本中,有放回的先后抽取两个样本,抽到同一个物种的概率就是Pi2,再将所有物种的概率相加并被1减去就得到了Simpson指数。也可以看出Simpson系数的范围在0-1之间。
群落的丰富度越高,且不同物种分布越均匀,Simpson指数也就越大,越接近于1,也就代表着Alpha多样性越高。
Beta多样性指数
Beta多样性反映的是不同种群间生物多样性的比较。要想得到Beta多样性指数,首先要从得到不同样品之间的距离矩阵开始。
距离矩阵算法
| 基于独立OTU | 基于系统发育树 | |
|---|---|---|
| 加权 | Bray-curtis | weighted unifrac |
| 非加权 | Jaccard | Unweighted unifrac |
距离矩阵的算法主要就是以上这四种,通过这些算法来得到样本间的距离最后得到距离矩阵。加权和不加权的区别在于是否不仅考虑物种的有无还要考虑物种间丰度的距离。基于OTU的算法是根据不同物种在不同样品中的分布不同(加权或不加权)来计算距离的,而基于系统发育树的算法则考虑的是不同样品间的物种进化关系。
一般来说基于OTU和系统发育树的计算方法都要使用。对于选择加权算法还是非加权算法,加权算法对于丰度较高的物种敏感性更高,非加权算法对稀有物种的敏感性更高。
PCA分析
主成分分析(Principal componentanalysis)。PCA采用降维的思想,将组成复杂的数据信息(样本中包含大量物种信息,没有已知的坐标轴可以解释分布)进行降维排序,寻找能最大程度反应规律的坐标系。
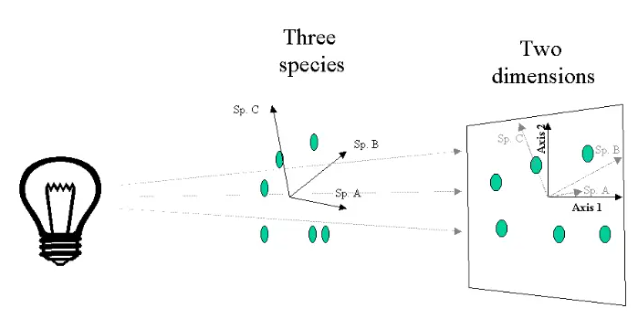
最后得到的结果横纵轴分别代表第一第二主成分,并且会标注该主成分对样品OTU差异的贡献比例。同组样品的距离远近说明样品的重复性强弱,不同组样本的远近就反映了组间的群落差异。
PCoA分析
主坐标分析(Principal co-ordinates analysis)。PCoA分析同样采用降维的思想对样本关系进行低维平面的投影,不同的是,PCA分析是对样本中物种丰度数据的直接投影,而PCoA则是将样本数据经过不同距离算法获得样本距离矩阵的投影,在图形中样本点的距离等于距离矩阵中的差异数据距离。
将样品间的距离在坐标轴上进行不同角度投影,找到最能够反映原始距离分布的前两个坐标轴进行数据输出。 与PCA不同,PCoA是对样品间距离(连线)的投影,在二维平面上展示的是样品间距离的信息,而不是样品的位置信息(也就是说其实PCoA在多维得到的并不是一个有位置信息的图,点之间的位置关系都是相对存在的)。
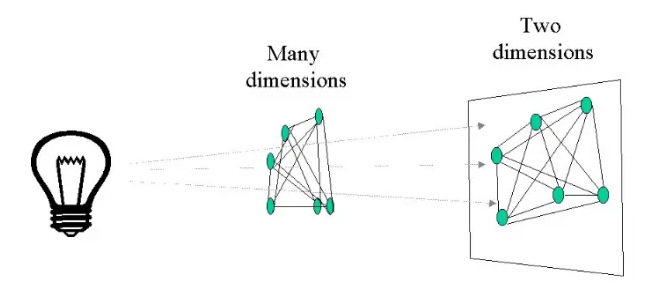
PCoA的结果图选择输入不同的相似距离矩阵(算法)得到的结果存在一定程度的差异。最后得到的结果横纵轴分别代表第一第二主坐标,并且会标注该主坐标对样品距离矩阵差异的贡献比例。同组样品的距离远近说明样品的重复性强弱,不同组样本的远近就反映了组间的样本距离差异。
UMDS分析
非量度多维标度分析法(Non-metric multidimensional scaling)。NMDS分析与PCoA分析的相同点在于两者都使用样本相似性距离矩阵进行降维排序分析,从而在二维平面上对样本关系做出判断。不同于PCoA分析,NMDS弱化了对实际距离数值的依赖,更加强调数值间的排名(秩次),例如三个样本的两两相似性距离为(1,2,3)或(10,20,30)在NMDS分析上的排序一致,所呈现的效果相同。
有一个stress值专门用来评价UMDS的结果图降维效果,越接近于0说明越能反映数据排序的真实情况,一般要求<0.1。
选择不同的距离矩阵算法同样也会对UMDS结果图产生影响。同组样本点距离远近说明了样本的重复性强弱,不同组样本的远近则反应了组间样本距离在秩次(数据排名)上的差异。另外,NMDS是距离值的秩次(数据排名)信息的评估,图形上样本信息仅反映样本间数据秩次信息的远近,而不反映真实的数值差异,横纵坐标轴并无权重意义,横轴不一定比纵轴更加重要。
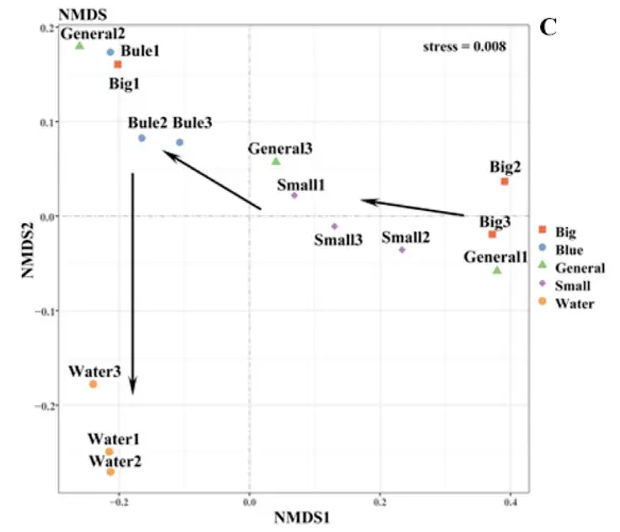
小结
| PCA | PCoA | NMDS | |
|---|---|---|---|
| 输入数据 | OTU丰度表 | 相似性距离表 | 相似性距离表 |
| 常见分析点 | OTU分析 | Beta多样性分析 | Beta多样性分析 |
| 分析信息 | 原始OTU数据 | 原始相似性距离 | 相似性距离数值排序 |
| 是否含stress值 | 否 | 否 | 是 |
| 坐标是否有权重意义 | 是 | 是 | 否 |